

本記事では、Lazuliでソフトウェア開発者として働くメンバーがラスベガス現地で参加したGoogle Cloud Next '24でデータベースについて学んだこと、そしていくつかの基準を用いて当社のニーズに適したものを選ぶ方法について共有したいと思います。
こんにちは、つきと申します。私は東京のLazuli Inc.でソフトウェア開発者として働いています。最近、私はラスベガスのGoogle Cloud Next ’24に参加する機会を得ました。
この素晴らしいイベントに参加する機会を与えてくれた私たちの会社の皆さんに感謝したいと思います。これは私が初めてアメリカに行く機会でした。

Google Cloud Nextは、Google Cloudからのニュースと更新を紹介する年次イベントです。このイベントは主に、テックスタックでGoogle Cloudを使用する世界中のソフトウェア開発者が集まります。参加者は多くのセッションを通じて、新機能やサービスの詳細について学ぶことができます。

参加者は、初心者向けの紹介から高度な技術的な深掘りまで、700以上の異なるコースから選ぶことができました。私はこれらのいくつか、特にGoogle Cloud上のデータストレージオプションに焦点を当てたものに参加しました。
Google Cloud Next ’24では、主な焦点は急速に人気を集めているGenAIへのアップデートでした。しかし、私は特にデータストアに興味があるので、主にそれらを取り上げた学習セッションに参加しました。
本記事では、Google Cloud Nextでデータベースについて学んだこと、そしていくつかの基準を用いて私たちのニーズに適したものを選ぶ方法について共有したいと思います。
カテゴリー
データベースの選択に深く入る前に、まずGoogle Cloudが提供するデータストアの種類を学びましょう。
主に三つのデータベースのカテゴリーがあります。
- 関係データベース(RDB):データをテーブル、行、列に整理するデータベースです。データの構造を定義するためにスキーマを使用します。RDBは、複数の操作やクエリを必要とする複雑なトランザクションを必要とするアプリケーションに適しています。
- NoSQLデータベース:これらは、大量の構造化および非構造化データを処理するのに理想的なスキーマレスデータベースです。非常にスケーラブルで、高いパフォーマンスを提供します。
- 分析データベース:これらは大規模なデータセットで複雑な分析クエリを実行するために設計されています。読み込み重視のワークロードに最適化されており、ペタバイトのデータを処理することができます。
詳細
Google Cloudは、特定の使用事例に合わせてカスタマイズされた複数のデータベースオプションを提供しています。

- Memorystore:RedisおよびMemcachedの完全に管理されたインメモリデータストアサービス。レイテンシーを減らし、パフォーマンスを向上させるキャッシュが必要なアプリケーションにとって強力な選択です。クイックデータアクセスを必要とするユースケースに理想的です。
- Cloud SQL:設定、保守、管理、およびクラウド内のリレーショナルMySQL、PostgreSQL、およびSQL Serverデータベースの管理を簡素化するフルマネージドなリレーショナルデータベースサービス。
- AlloyDB:最適なパフォーマンスと信頼性を目指して設計された高速で分散型のPostgreSQLデータベース。効率的なデータ処理と分散型ワークロード管理が必要なアプリケーションにとって堅牢なソリューションを提供します。
- Cloud Spanner:大規模で、ミッションクリティカルな、リレーショナルおよびトランザクションワークロードに最適なグローバル分散データベースサービス。リレーショナルデータベース構造の利点と非リレーショナル水平スケールを組み合わせます。
- Cloud Bigtable:大規模な運用ワークロードに理想的な低レイテンシー、スケーラブルなNoSQLデータベース。任意のサイズのIoT、ユーザーアナリティクス、および財務データ分析からデータを収集し保持するために設計されています。
- Firestore:自動スケーリング、高パフォーマンス、そして簡単なアプリケーション開発のために構築されたNoSQLドキュメントデータベース。グローバルスケールでデータを保存、同期、クエリするプロジェクトにとって優れた選択です。
Google Cloudは、マルチメディアのストレージ操作のためのCloud Storageのようなオブジェクトストレージと、高性能ファイル操作のためのCloud Filestoreのようなファイルストレージなども提供しています。
Cloud Nextのハイライトの一つは、ビジネスの敏捷性を目指した、サーバーレスで非常にスケーラブル、コスト効果の高いマルチクラウドデータウェアハウスであるBigQueryでした。テラバイトからペタバイトのデータを、SQLを使用して驚異的な速度で分析する能力を持っているため、大量のデータセットを扱うビジネスにとってはゲームチェンジャーと見なされています。
Google Cloud Nextでは、すべてのデータストアオプションが優れた品質であり、競合他社を上回るものとして提示されました。しかし、これが常に必ずしも当てはまるわけではありません。ユーザーは複数の指標に基づいて自分たちのユースケースを評価する必要があります。
これらのストレージオプションそれぞれには、強みと理想的なユースケースがあります。特定のニーズに最適なソリューションを選択する際には、これらを理解することが重要です。
💡 GenAIアプリケーションの人気が高まっており、Google Cloudは現在すべてのデータベースでベクトル検索のサポートを提供しています。
指標
データベースを比較するための指標を設定しましょう。全ての問題や使用ケースに適合する普遍的な基準を作るのは難しいかもしれませんが、考慮すべきいくつかの重要なポイントがあります:
- データタイプ:データは構造化されていますか?
- データサイズ:データの推定量はどのくらいですか?
- クエリの複雑さ:どのタイプのクエリ要件が必要ですか?
- アクセス頻度:どのくらい頻繁にサービスがデータにアクセスしますか?
- レイテンシ:データの取得に許容できるレイテンシは何ですか?
- パフォーマンス:必要なパフォーマンスレベルは何ですか?
- スケーラビリティ:データは時間とともに成長し、データベースはこの成長を処理できますか?
- コスト:運用コストは、データの入出力、ストレージ、インデックスを含めてどのくらいですか?
他にも考えられる基準としては以下のようなものがあります:
- 可用性:データベースは必要なときに利用可能ですか?そのアップタイムは何ですか?
- 冗長性:データベースはデータの可用性を確保するためのデータ複製と自動フェイルオーバーサポートを提供していますか?
- 地理的分布:データは異なる地域に分散する必要があり、データベースはこの分散をサポートしていますか?
- 災害復旧:データベースは、潜在的な損失や破損に対してあなたのデータを保護する強固な災害復旧計画を持っていますか?
- 維持管理性:データベースを管理・維持するのはどれくらい簡単ですか?
- 互換性:データベースはあなたの既存のテックスタックとどれくらいよく統合しますか?
- セキュリティ:データの機密性はどの程度で、データベースはどのようなセキュリティ対策を提供しますか?
- コンプライアンス:データベースはあなたのビジネスに適用される規制とコンプライアンス要件を満たしていますか?
- 機能:データベースはあなたのアプリケーションに必要な機能を提供しますか?
- トランザクションサポート:あなたのアプリケーションは複雑なトランザクションを必要とし、その場合、データベースはそれをサポートしますか?
- ベンダーロックイン:サービスプロバイダーへの依存度にあなたは快適ですか?必要に応じてデータを別のサービスに移行するのはどれくらい簡単ですか?
- 成熟度:データベース技術はどれくらい成熟していますか?それは実績があるか、またはまだ開発の初期段階にあるのですか?
- サポート:データベースにはどのようなサポートが利用可能ですか?これにはコミュニティサポート、プロフェッショナルサポート、ドキュメンテーションが含まれるかもしれません。
これらのほとんどはGoogle Cloudによって完全にカバーされているか、またはGoogle Cloudのデータベースを選択する際には重要でないため、この記事ではこれらについては取り扱いません。
データベースのオプションは、費用対効果の観点からも評価するべきです。ストレージ、データの入力と出力、インデックスのコストを含む運用コストを考慮してください。また、時間とともにデータが増加する可能性についても考え、データベースがこの成長を効率的かつ手頃な価格で処理できるかどうかを考えてください。あなたのサービスに提供する価値よりもコストがかかるデータベースは目的を逸していることを覚えておいてください。
比較
Memorystore、Cloud SQL、AlloyDB、Cloud Spanner、Cloud Bigtable、Firestore、BigQueryを比較します。BigQueryはデータベースよりもデータウェアハウスに近いですが、一応取り上げたいと思います。
<データタイプ>
まず、取り扱うデータのタイプを理解することが重要です。構造化データの場合、Cloud SQLやAlloyDBのようなリレーショナルデータベースが適しています。非構造化データの場合、FirestoreやCloud BigtableのようなNoSQLデータベースがより適しています。大規模な構造化データには、Cloud Spannerが優れた選択です。
| データベース | データタイプ |
| Memorystore | メモリ内、構造化データに適しており、高速なデータアクセスが必要なアプリケーションに理想的 |
| Cloud SQL | リレーショナル、複数の操作やクエリを必要とする複雑なトランザクションが必要なアプリケーションに適しています |
| AlloyDB | リレーショナル、構造化、効率的なデータ処理と分散ワークロード管理が必要なアプリケーションに理想的 |
| Cloud Spanner | リレーショナル、構造化、大規模でミッションクリティカルなリレーショナルおよびトランザクショナルワークロードに完璧 |
| Cloud Bigtable | NoSQL、構造化および非構造化データの両方に適しており、大規模な運用ワークロードに理想的 |
| Firestore | NoSQL、非構造化データに適しており、データの格納、同期、およびグローバルスケールでのクエリが必要なプロジェクトに優れています |
| BigQuery | 分析、構造化および非構造化データの両方に適しており、大規模なデータセットに対して複雑な分析クエリを実行するために設計されています |
<データサイズ>
次に、データのサイズを考えてみましょう。小規模から中規模のデータセットには、Cloud SQLまたはFirestoreがより適しているかもしれません。より大きなデータセットには、その優れたスケーラビリティのために、Cloud SpannerまたはCloud Bigtableがより適合するかもしれません。
| データベース | データサイズ |
| Memorystore | 小 – 頻繁にアクセスされるデータのキャッシングに最適 |
| Cloud SQL | 小から中 – データストレージのニーズが適度なアプリケーションに適しています |
| AlloyDB | 中から大 – 分散ワークロードを通じて効率的なデータ処理が必要なアプリケーションに設計されています |
| Cloud Spanner | 非常に大きい – 大規模で、ミッションクリティカルなリレーショナルおよびトランザクションワークロードを処理します |
| Cloud Bigtable | 非常に大きい – 大規模な運用負荷に最適; IoT、ユーザーアナリティクス、および金融データ分析からのデータを収集し保持します |
| Firestore | 小から中 – データの頻繁な保存、同期、およびクエリが必要なアプリケーションに最適 |
| BigQuery | 非常に大きい – 広範なデータセットに対する複雑な分析クエリを実行するために構築されています |
<クエリの複雑さ>
次に、クエリの複雑さを考えてみましょう。あなたのクエリが単純ならば、FirestoreまたはCloud Bigtableが十分かもしれません。しかし、複数のテーブル、サブクエリ、集約関数、または分析関数を含む複雑なクエリの場合、Cloud SQLまたはAlloyDBを検討することをお勧めします。あなたのクエリが非常に複雑で大量のデータセットを含む場合、Cloud Spannerが最良の選択かもしれません。
| データベース | クエリの複雑さ |
| Memorystore | シンプルなクエリに適しています |
| Cloud SQL | 複数のテーブル、サブクエリ、集約関数を含む複雑なクエリを処理します |
| AlloyDB | 複数のテーブル、サブクエリ、集約関数を含む複雑なクエリを処理します |
| Cloud Spanner | 大規模なデータセットを含む非常に複雑なクエリに適しています |
| Cloud Bigtable | 中程度の複雑さのクエリを処理します |
| Firestore | シンプルなクエリに適しています |
| BigQuery | 大規模なデータセットで非常に複雑な分析クエリを処理します |
<アクセス頻度>
次に、データがどれくらいの頻度でアクセスされるかを考慮する必要があります。頻繁にデータへのアクセスが必要なアプリケーションには、FirestoreまたはCloud Bigtableが最適な選択肢かもしれません。逆に、データへのアクセス頻度が比較的低いアプリケーションには、Cloud SQLまたはBigQueryがより適している可能性があります。データを極めて迅速にアクセスする必要があるシナリオでは、Memorystoreのようなインメモリソリューションが最も適切な選択肢となるかもしれません。
| データベース | アクセス頻度 |
| Memorystore | 高 – 頻繁で迅速なデータアクセスが必要なアプリケーションに最適化 |
| Cloud SQL | 中 – 適度なデータアクセス要件を持つアプリケーションに適しています |
| AlloyDB | 中 – データへの定期的なアクセスが必要なアプリケーションに設計されています |
| Cloud Spanner | 高 – データへの頻繁なアクセスが必要な大規模アプリケーションに最適 |
| Cloud Bigtable | 高 – 高速なデータアクセスが必要な大規模な運用ワークロードに設計されています |
| Firestore | 高 – データの頻繁な保存、同期、およびクエリが必要なアプリケーションに最適 |
| BigQuery | 低 – 大規模なデータセットに対する複雑な分析クエリにより適しており、頻繁なデータアクセスには適していません |
<レイテンシ>
データベースのレイテンシは、データ操作が結果を返すまでの時間です。あなたのアプリケーションがリアルタイムの操作に低レイテンシを必要とする場合、Firestore、Cloud Bigtable、またはMemorystoreが良い選択肢となるかもしれません。レイテンシが重要な要素ではないアプリケーションの場合、Cloud SQL、AlloyDB、またはBigQueryが適している可能性があります。
| データベース | レイテンシ |
| Memorystore | 非常に低い – メモリ内の性質により、データの取得はほぼ瞬時であり、リアルタイムのアプリケーションに最適です。 |
| Cloud SQL | 低い – 管理されたサービスで最適化されたインフラストラクチャを備えているため、一般的な使用ケースでのデータアクセスが迅速です。 |
| AlloyDB | 低い – 高速な能力により、データ取得時間が短縮され、効率的なデータ処理が支援されます。 |
| Cloud Spanner | 低い – グローバルに分散したアーキテクチャにより、大規模でミッションクリティカルなワークロードでも低レイテンシを保証します。 |
| Cloud Bigtable | 低い – 高速アクセス用に設計されているため、大規模な運用ワークロードに対して低レイテンシを提供します。 |
| Firestore | 低い – 自動スケーリングと高性能設計により、グローバルスケールのプロジェクトに対して低レイテンシを保証します。 |
| BigQuery | 中 – 主に大規模なデータセットに対する複雑な分析クエリを目的として設計されているため、他のものと比べてレイテンシが少し高いです。ただし、意図された使用ケースには依然として効率的です。 |
<パフォーマンス>
パフォーマンスとは、データベースが操作を実行する速度のことです。リアルタイムの操作に高いパフォーマンスが求められるアプリケーションの場合、Firestore、Cloud Bigtable、またはMemorystoreが良い選択肢となるかもしれません。パフォーマンスが重要な要素ではないアプリケーションの場合、Cloud SQL、AlloyDB、またはBigQueryが適しているかもしれません。
| データベース | パフォーマンス |
| Memorystore | 高 – インメモリデータストアとして、リアルタイムアプリケーションのための迅速なデータアクセスを提供します。 |
| Cloud SQL | 中 – 最適化されたインフラストラクチャにより、ほとんどのユースケースに適した高速なデータアクセスを提供します。 |
| AlloyDB | 高 – 高速な機能により、データ操作が効率的に必要なアプリケーションにとって理想的な迅速なデータ処理を保証します。 |
| Cloud Spanner | 高 – グローバルに分散したアーキテクチャのため、大規模でミッションクリティカルなワークロードに適した高速なデータ操作を提供します。 |
| Cloud Bigtable | 高 – 高速なデータ操作のために設計されており、大規模なオペレーショナルワークロードに最適です。 |
| Firestore | 中 – ドキュメントデータベースとして、頻繁なデータストレージ、同期、およびクエリが必要なアプリケーションの高性能を提供します。 |
| BigQuery | 中 – データウェアハウスとして、大規模なデータセットに対する複雑な分析クエリの実行に設計されており、高速なデータ操作には適していません。 |
<スケーラビリティ>
スケーラビリティは、データベースが増加する作業量を処理する能力です。時間とともにデータが増加することを予想するなら、ニーズに合わせてスケールできるデータベースを選ぶべきです。Firestore、Cloud Bigtable、およびCloud Spannerは大量のデータを処理するために設計されており、ニーズに応じてスケールアップまたはスケールダウンできます。
| データベース | スケーラビリティ |
| Memorystore | 中 – それはまあまあのスケーラビリティを提供しますが、インメモリデータストアであるため、そのサイズは利用可能なメモリによって制限されます。 |
| Cloud SQL | 中 – Cloud SQLは適度なワークロードの増加を処理でき、安定した成長を持つアプリケーションに適しています。 |
| AlloyDB | 高 – AlloyDBは分散ワークロードを効率的に処理するように設計されており、変動するか急速に成長するデータニーズを持つアプリケーションにとって非常にスケーラブルです。 |
| Cloud Spanner | 高 – そのグローバルに分散したアーキテクチャのおかげで、Cloud Spannerは最大のワークロードでも横にスケールアウトして処理でき、大規模アプリケーションに理想的です。 |
| Cloud Bigtable | 高 – Cloud Bigtableは大きなワークロードを処理するように設計されており、ニーズに応じてスケールアップまたはダウンできるため、大規模なオペレーショナルワークロードに適しています。 |
| Firestore | 中 – Firestoreはデータのニーズに合わせてスケールアップまたはダウンできますが、中程度のデータストレージニーズを持つアプリケーションにより適しています。 |
| BigQuery | 高 – BigQueryは大きなデータセットを分析するために設計されており、データ分析タスクにとって非常にスケーラブルです。 |
<コスト>
データベースのコストは、保存しているデータの量、実行している操作の数、ネットワークトラフィックの量など、いくつかの要素に基づいて変動します。 FirestoreとCloud SQLは、一般的に小さなデータセットに対してはよりコスト効果が高いですが、Cloud SpannerとCloud Bigtableは大きなデータセットに対してはよりコスト効果が高いかもしれません。
| データベース | 費用 |
| Memorystore | 高 – メモリ内の性質と迅速なデータアクセスのため、特に大きなデータセットの場合、コストは急速に上昇する可能性があります。 |
| Cloud SQL | 中 – フルマネージドサービスとして、価格にはストレージ、操作、ネットワークトラフィックのコストが含まれています。中程度のデータストレージニーズにはコスト効果的かもしれません。 |
| AlloyDB | 高 – 高速な機能と効率的なデータ処理のため、特に大規模な分散ワークロードの場合、コストが高くなる可能性があります。 |
| Cloud Spanner | 高 – グローバルに分散したアーキテクチャと大規模なワークロードのためのスケーラビリティにより、特に大規模なミッションクリティカルなワークロードの場合、コストは高くなります。 |
| Cloud Bigtable | 中 – 価格設定はストレージ、ネットワークトラフィック、および行われた操作に基づいています。大規模なワークロードのスケーラビリティにもかかわらず、使用状況によってはコストが適度になる可能性があります。 |
| Firestore | 中 – 価格設定は行われた読み取り、書き込み、削除の数と使用されたストレージの量に基づいています。頻繁にデータ操作を行うアプリケーションの場合、コストは通常、適度です。 |
| BigQuery | 低 – 複雑な分析クエリのために設計されたデータウェアハウスとして、価格はこれらのクエリによって処理されるデータの量に基づいています。これにより、大きなデータセットに対してはよりコスト効果的になる可能性があります。 |
以下は、データベースを選択する際に考慮すべきさまざまな基準の包括的な要約です。これらの基準は、Google Cloudが提供するさまざまなデータベースオプションの特性に基づいています。
| 基準 / データベース | データタイプ | データサイズ | クエリの複雑さ | アクセス頻度 | レイテンシ | パフォーマンス | スケーラビリティ | コスト |
| Memorystore | 構造化データに最適 | 小規模なデータサイズに最適 | 単純なクエリを処理 | 高頻度のアクセス | データの即時取得のための極めて低いレイテンシ | リアルタイムのアプリケーションのための超高速パフォーマンス | 中程度のスケーラビリティ | 特に大規模なデータセットの場合は高コスト |
| Cloud SQL | 構造化データに最適 | 中規模なデータサイズに適している | 複雑なクエリを処理可能 | 中頻度のアクセス | データの迅速なアクセスのための低レイテンシ | ほとんどのユースケースに適した高速パフォーマンス | 安定した成長を持つアプリケーションのための適度なスケーラビリティ | ストレージ、操作、ネットワークトラフィックを考慮した中程度のコスト |
| AlloyDB | 構造化データの設計 | 大規模なデータサイズを処理可能 | 複雑なクエリを処理可能 | 中頻度のアクセス | 高速機能による低レイテンシ | データ操作の効率化のための超高速パフォーマンス | 変動するまたは急速に成長するデータニーズを持つアプリケーションのための高スケーラビリティ | 特に大規模で分散したワークロードのための高コスト |
| Cloud Spanner | 構造化データに最適 | 超大規模なデータサイズに最適 | 複雑なクエリを収容 | 高頻度のアクセス | 大規模でミッションクリティカルなワークロードでも低レイテンシ | 全球に分散したアーキテクチャによる超高速パフォーマンス | 最大のワークロードも処理可能な高スケーラビリティ | 特に大規模でミッションクリティカルなワークロードの場合は高コスト |
| Cloud Bigtable | 構造化データと非構造化データの両方に適しています | 超大規模なデータサイズに最適 | 中程度の複雑さのクエリを処理 | 高頻度のアクセス | 高速データアクセスのための低レイテンシ | 大規模運用ワークロードのための超高速パフォーマンス | ニーズに応じて調整可能な高スケーラビリティ | 使用量に応じた中程度のコスト |
| Firestore | 非構造化データに優れています | 中規模なデータサイズに最適 | 単純なクエリを処理 | 高頻度のアクセス | グローバルスケールのプロジェクトのための低レイテンシ | データの頻繁なストレージ、同期、およびクエリのための高速パフォーマンス | 中規模のデータストレージニーズにより適している中程度のスケーラビリティ | 頻繁なデータ操作を持つアプリケーションのための中程度のコスト |
| BigQuery | 構造化データと非構造化データの両方に適しています | 超大規模なデータサイズに最適 | 複雑なクエリを処理可能 | 低頻度のアクセス | 予想されるユースケースに効率的な中程度のレイテンシ | 大規模なデータセットに対する複雑な分析クエリのために設計された中程度のパフォーマンス | データ分析タスクのための高スケーラビリティ | 特に大規模なデータセットの場合は低コスト |
そして、以下はデータベースを選ぶためのチートシートになります。
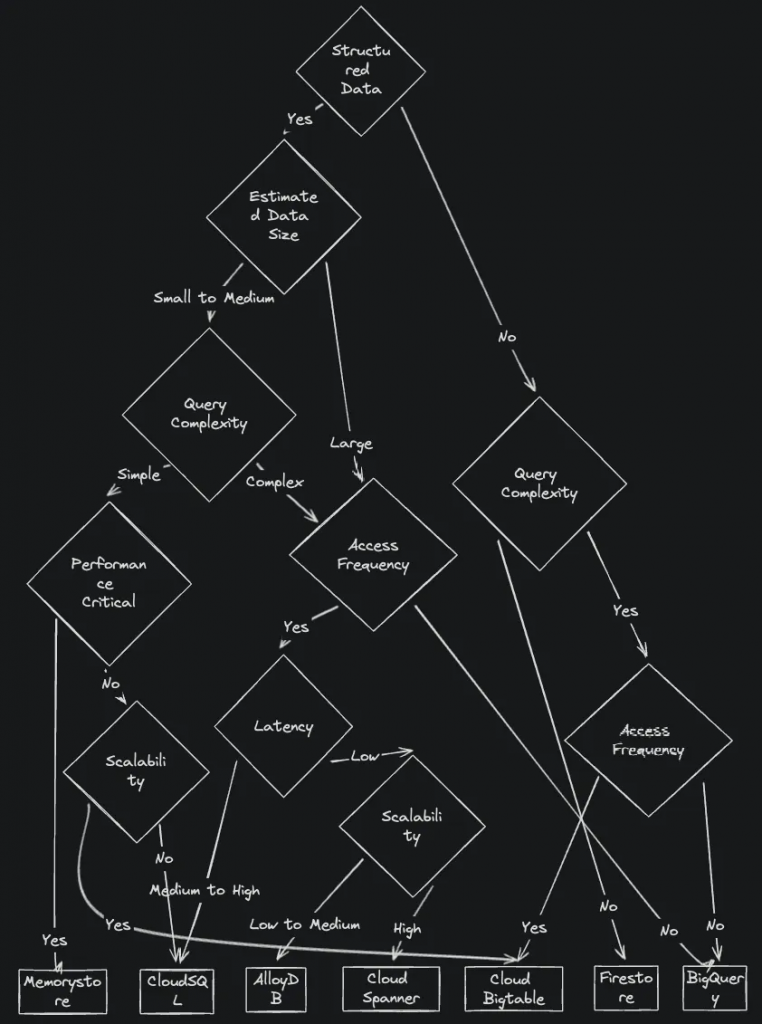
私は、NoSQLがこの時代の問題の解決策だと信じていました。しかし、私の個人的な経験から言うと、時間が経つにつれて、クエリ要件が一般的にはより複雑になることに気づきました。
すべての要件を最初から予測するのは難しいです。そのため、適切なオプションの選択を始めるときには、データサイズ、クエリの複雑さ、アクセス頻度を最初に考慮することをお勧めします。
概要
Google Cloud Next ’24で学んだことや私自身の経験から、データベースを選ぶ際に全ての要件を満たすようなソリューションはあまり存在しません。アプリケーションの特定のニーズと要件を考慮することが重要であり、それぞれの選択に伴うトレードオフも考慮に入れる必要があります。そうすることで、情報に基づいた最善の決定を下すことができます。技術が進化し続けるにつれて、これらのデータベースがどのように適応し、改善して、私たちのニーズをよりよく満たすためにどのように進化するのかを見るのが楽しみです。
そして、この記事を読んでいただき、本当にありがとうございます。あなたが次のプロジェクトのデータベースを選ぶ際に、指標に基づいた決定を下す助けになることを願っています。
本記事は以下の”Google Cloud Next 24 recap: How to choose the right datastore for your use case”を翻訳したものになります。